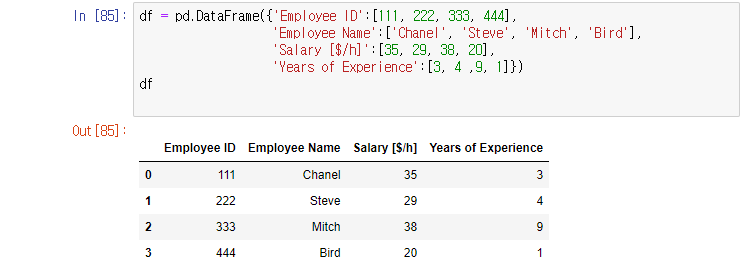
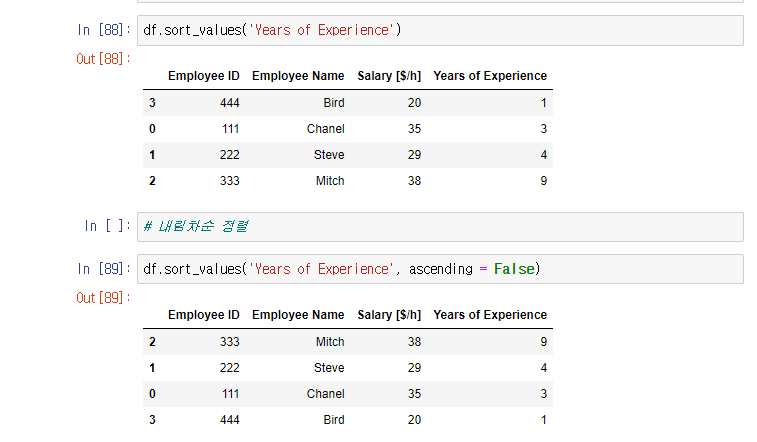
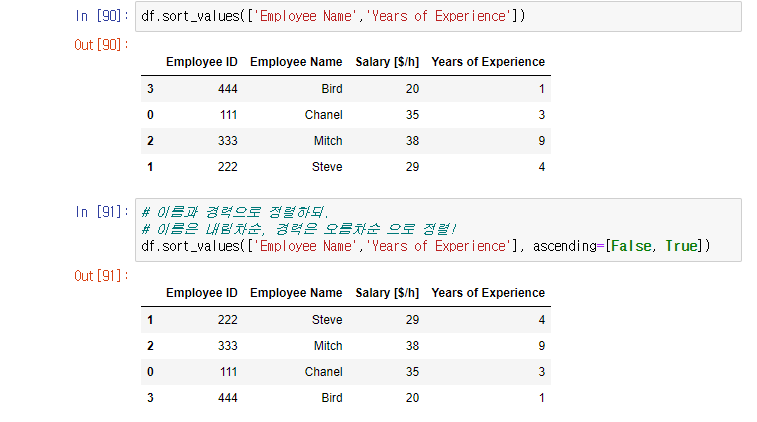
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sb
%matplotlib inline
df = pd.read_csv('../data/pokemon.csv')기본적인 라이브러리를 import하고 csv파일을 pd.read_csv()로 읽어와 df라는 변수에 저장했다.
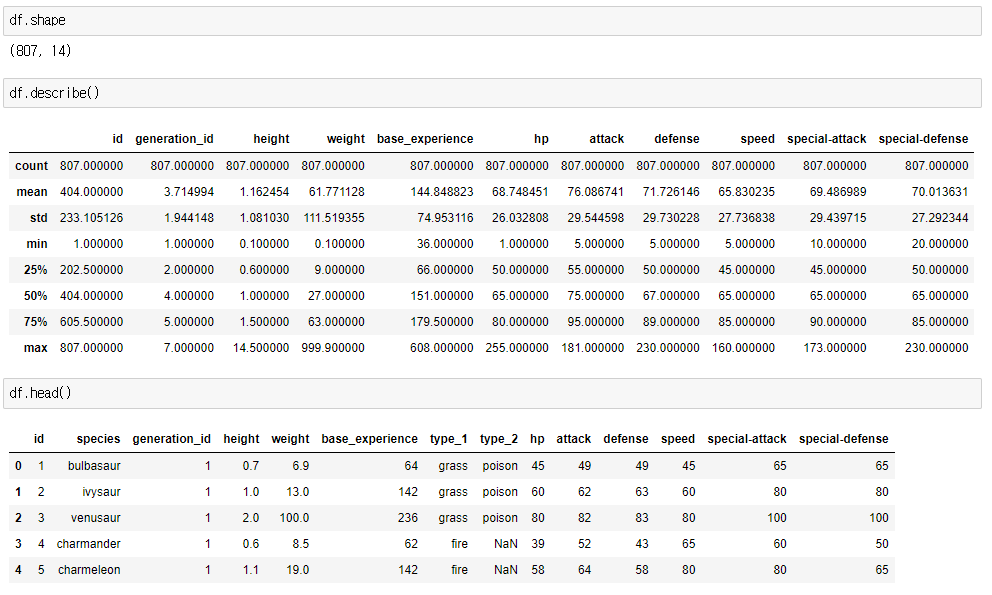
generation_id column에 관한 차트를 그리기 위해 categorical data인지 확인해본다.
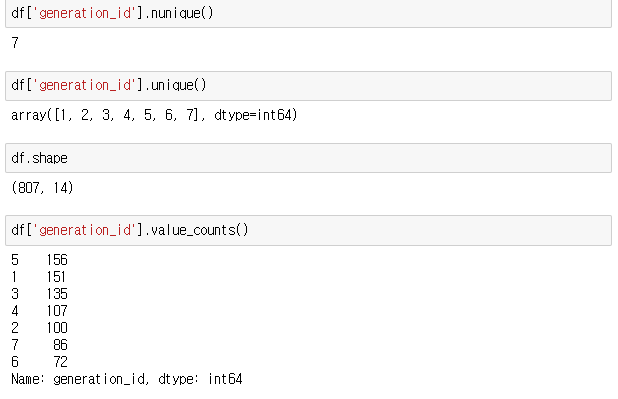
807행 중 7개의 카테고리로 나눠져있다.
base_color = sb.color_palette()[2]
my_order = df['generation_id'].value_counts().index
sb.color_palette()를 통해 색을 지정하고 value_counts().index로 내림차순 인덱스를 얻어서 x에 원하는 column을 대입했다.
'데이터 분석 > 데이터 시각화' 카테고리의 다른 글
| 파이썬 hist2d() 히트맵 (0) | 2022.05.03 |
|---|---|
| 파이썬 scatter(), regplot() Bivariate (여러 개의 변수) Visualization 방법 (0) | 2022.05.03 |
| 파이썬 hist() 히스토그램 (0) | 2022.05.03 |
| 파이썬 pie charts (0) | 2022.05.03 |
| 파이썬 matplotib 기본적인 plot (0) | 2022.05.03 |