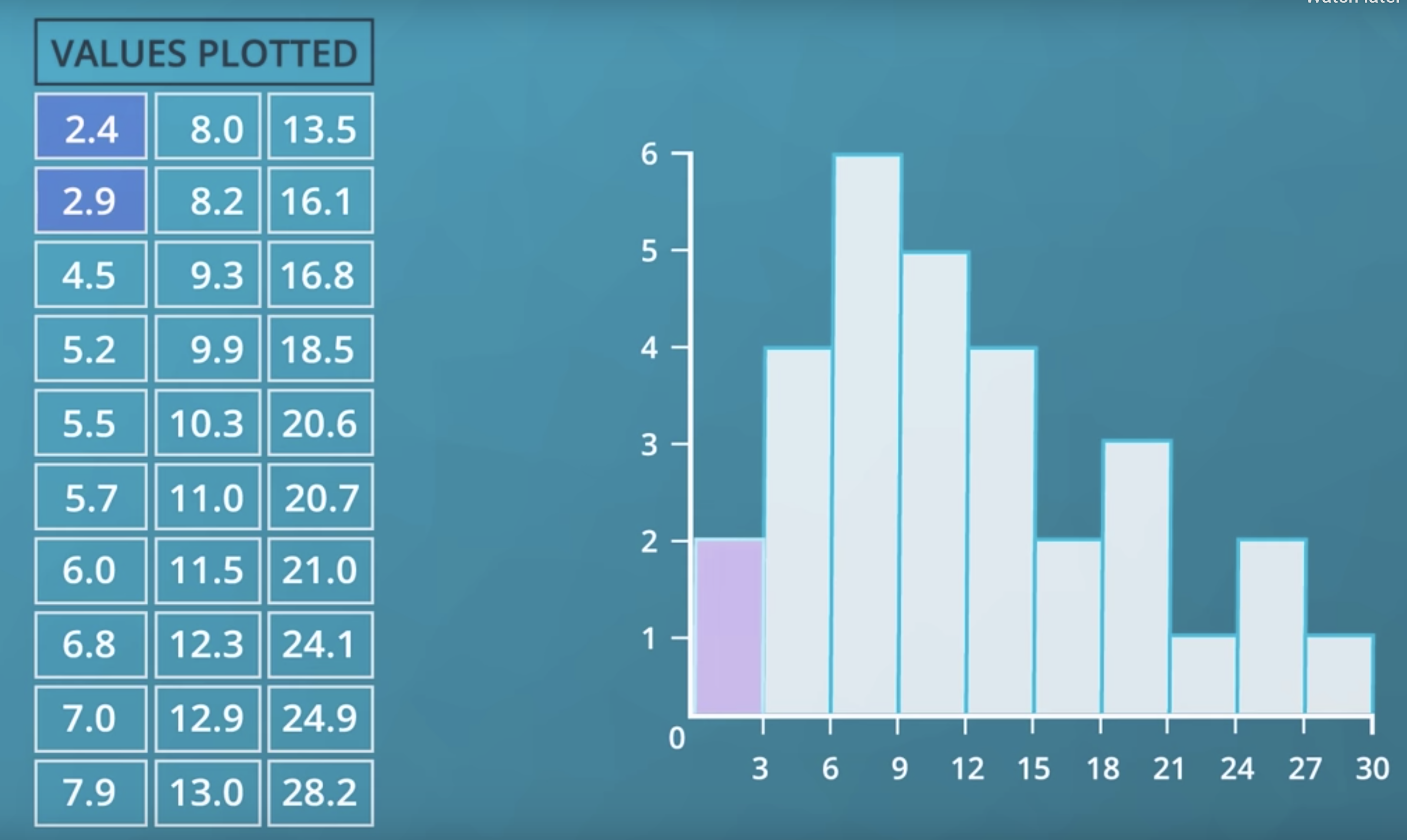
구간을 설정하여 해당 구간에 포함되는 데이터가 몇개 있는 세는 차트를 히스토그램이라고 한다. 구간을 전문용어로! bin 이라고 부른다, bin 이 여러개니까, bins라고 부른다, 히스토그램의 데이터는 동일하지만, 구간을 어떻게 나누냐에 따라서, 차트 모양이 여러가지로 나온다.
data
위는 예제에 쓸 데이터다.
hist
hist(data = 데이터프레임, x = 데이터프레임의 열, rwidth = 막대 넓이, bins = 막대 간격)을 통해 그래프를 그린다.