# import libraries
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import random
import seaborn as sns
from fbprophet import Prophet
df = pd.read_csv('avocado.csv', index_col = 0)
df = df.sort_values(by='Date')
라이브러리와 데이터를 import 해준다. Prophet 분석을 위해 Date와 AveragePrice column만 가져와서 ds 와 y로 바꿔준다.
avocado_prophet_df = df[['Date', 'AveragePrice']]
avocado_prophet_df.columns = ['ds', 'y']Prophet 객체를 만들고 기존의 데이터로 학습시킨뒤 예측하고자 하는 기간을 정해서 predict 함수에 대입한다.
prophet = Prophet()
prophet.fit(avocado_prophet_df)
future = prophet.make_future_dataframe(365)
forecast = prophet.predict(future)prophet.plot(forecast)
plt.savefig('chart1.jpg')
prophet.plot_components(forecast)
plt.savefig('chart2.jpg')
'인공지능 > 머신러닝' 카테고리의 다른 글
| WordCloud에서 배경 모양을 바꾸는 방법 (mask) (0) | 2022.05.10 |
|---|---|
| 머신러닝에서 문자열 데이터를 숫자로 바꿔주는 CountVectorizer, analyzer 파라미터, fit_transform과 transform 함수 (0) | 2022.05.10 |
| 머신러닝에서 문자열 데이터를 처리하기 위해, 구두점 제거와 stopwords 사용하는 방법 (0) | 2022.05.10 |
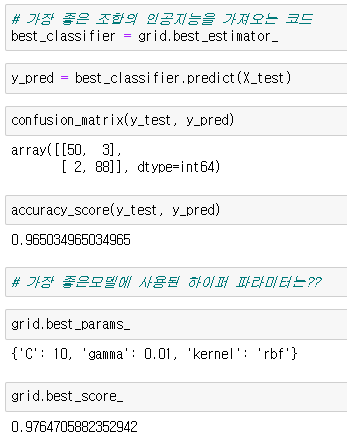
| 머신러닝 GridSearchCV 사용법 (0) | 2022.05.09 |
| WordCloud 라이브러리 사용법과 STOPWORDS 적용하는 방법 (0) | 2022.05.09 |