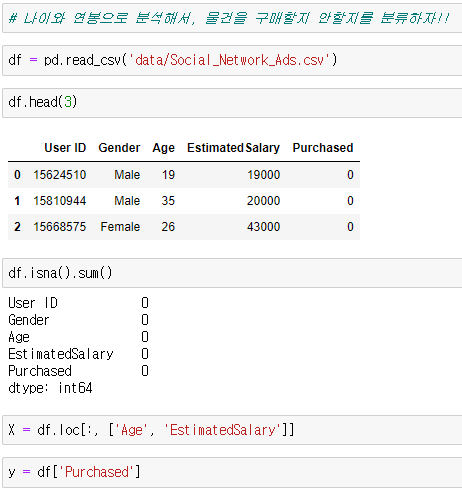
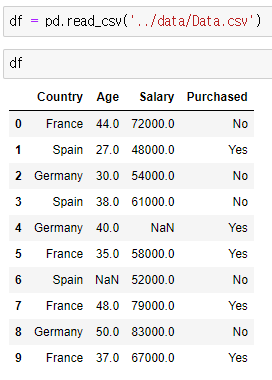
다음처럼 카테고리가 레이블링 되어 있는 데이터가 존재합니다.

새로운 데이터가 생겼을 때 내 주위에 몇개의 이웃을 확인해 볼 것인가를 결정한다. => K

새로운 데이터가 발생 시, Euclidean distance에 의해서, 가장 가까운 k개의 이웃을 택한다.

k 개의 이웃의 카테고리를 확인한다.

카테고리의 숫자가 많은 쪽으로, 새로운 데이터의 카테고리를 정한다.

라이브러리와 데이터를 불러오고, X와 y에 알맞게 대입한다.

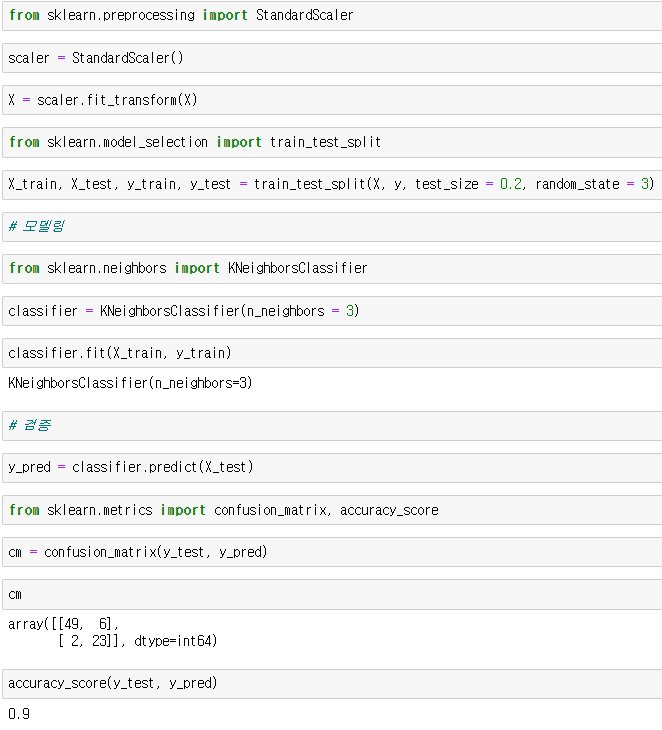
데이터의 범위를 스케일러에 대입한 후 훈련 셋과 테스트 셋을 분리 후 모델링하고 검증한다.
'인공지능 > 머신러닝' 카테고리의 다른 글
| 머신러닝 Decision Tree (0) | 2022.05.09 |
|---|---|
| 머신러닝 Support Vector Machine (0) | 2022.05.09 |
| 머신러닝 데이터 전처리 replace함수 이상한 값을 np.nan으로 바꾸고 np.nan을 처리하는 법(Nan 제거 또는 Nan을 다른 값으로) (0) | 2022.05.06 |
| 머신러닝 Logistic Regression 과 Confusion Matrix (0) | 2022.05.06 |
| 머신러닝 Linear Regression fit_transform,transform 함수 , 신규데이터 예측하는 법 (0) | 2022.05.06 |