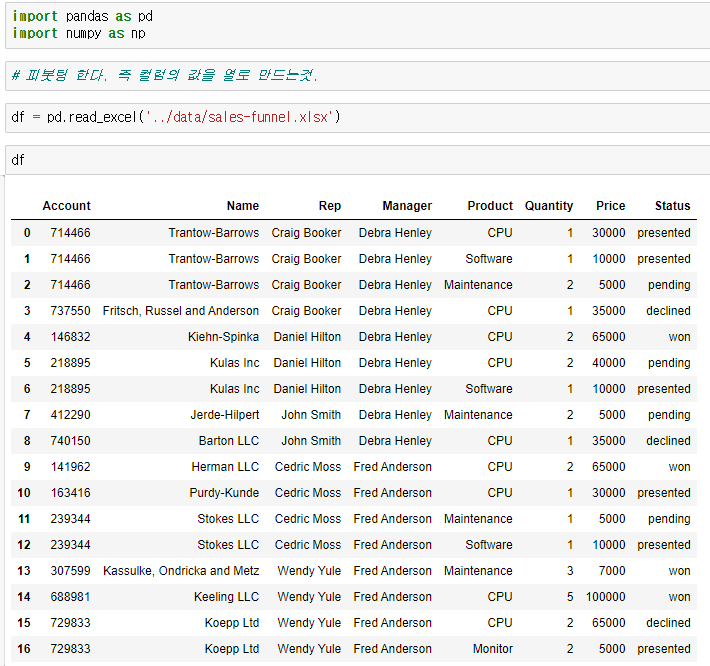
시리즈는 데이터프레임의 하위 자료형으로, 1개의 열이 시리즈이고 이 시리즈가 다수 모여 데이터프레임을 형성한다고 이해하면 쉽다.
import pandas as pd
index = ['eggs', 'apples', 'milk', 'bread']
data = [30, 6, 'Yes', 'No']
groceries = pd.Series(data = data, index = index)
grocerieseggs 30
apples 6
milk Yes
bread No
dtype: object시리즈 변수에 []기호 안에 숫자 인덱스나, 정해놓은 인덱스를 넣으면 되고, 두개이상 쓸때는 배열로 넣는다.
groceries[0]
groceries[['eggs','bread']]30
eggs 30
bread No
dtype: object다음은 데이터프레임을 생성해보겠다.
import pandas as pd
# We create a dictionary of Pandas Series
items = {'Bob' : pd.Series(data = [245, 25, 55], index = ['bike', 'pants', 'watch']),
'Alice' : pd.Series(data = [40, 110, 500, 45], index = ['book', 'glasses', 'bike', 'pants'])}
df = pd.DataFrame(data = items)
df
마찬가지로 데이터 억세스는 []로 한다.

두번째는 행과 열의 정보로, 데이터를 가져오는 방법 사람용인, 인덱스와 컬럼명으로 데이터를 억세스(가져오는) 방법이다. loc[인덱스, 컬럼명]

세번째는 컴퓨터가 자동으로 매기는 인덱스로, 행과 열을 가져오는 방법이다.

'데이터 분석 > pandas' 카테고리의 다른 글
| python pandas get_dummies함수 원핫인코딩 (0) | 2022.05.06 |
|---|---|
| 파이썬 pandas에서 DatetimeIndex와 to_datetime, to_timedelta,date_range,timedelta_range 함수 (0) | 2022.05.04 |
| 파이썬 pandas의 pivot_table() (0) | 2022.05.04 |
| 파이썬 pandas concat(), merge(), join() 데이터 합치기 (0) | 2022.05.02 |
| 파이썬 pandas sort_values() 데이터 정렬 (0) | 2022.04.29 |