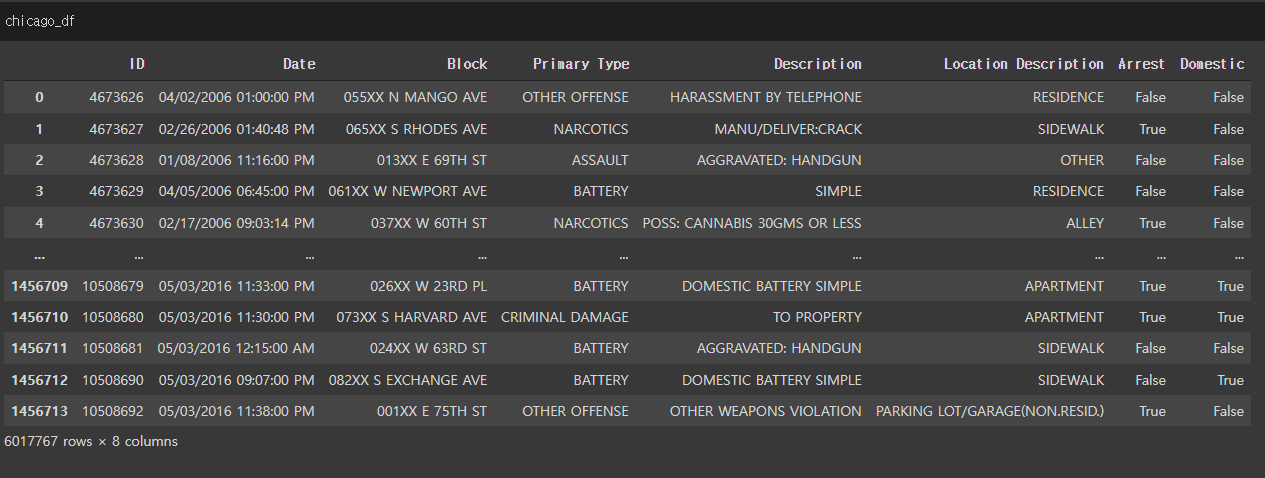
데이터를 import 후 pivot_table함수로 collaborative filtering format으로 변경한다.

최소 80개이상 데이터가 있는 것만 상관계수를 뽑기 위해서 min_periods 파라미터에 80을 대입한다.
myRatings를 통해 추천을 받으려고한다. Movie Name column에서 nan값을 dropna하고 내림차순 정렬후 데이터프레임으로 만든 뒤 별점을 곱해서 weight column을 만든다. similar_movies_list에 정리하면 다음과 같다.


'데이터 분석 > pandas' 카테고리의 다른 글
| 파이썬 pandas Time Series 데이터를 처리할 때 resample함수와 이 함수를 사용하기 위해 인덱스를 설정하는 방법 (0) | 2022.05.12 |
|---|---|
| 파이썬 pandas Series의 dt 속성 사용법, weekday (0) | 2022.05.11 |
| 파이썬 pandas 데이터프레임의 날짜문자열 컬럼을, datetime64로 변경하는 법 to_datetime함수 (0) | 2022.05.11 |
| 파이썬 pandas read_csv함수의 error_bad_lines = False 파라미터 사용법 (0) | 2022.05.11 |
| 파이썬 pandas groupby() 함수 사용법 (0) | 2022.05.11 |